The Routing Drift
Routing drift happens when overlapping tool or skill descriptions cause an AI to route prompts to the wrong capability.
Routing drift happens when an AI system's tool or skill descriptions become too similar for the model to choose reliably. The failure is quiet: the model still picks a route, but it may pick the wrong one with confidence.
When Your AI Can't Tell Your Director Coach from Your VP Coach
If you are building on Claude Code, OpenAI Assistants, or any LLM platform that supports tool use, you have probably built something like this: a set of specialized skills — each with a short description that tells the model when to call it. The model reads every description, picks the best match for the user's prompt, and routes accordingly.
This works well with 5 skills. It works acceptably with 15. Somewhere past that, it starts breaking — and the failure mode is silent. The model doesn't throw an error when it picks the wrong skill. It just confidently executes the wrong one, and neither you nor the user knows it happened.
Here's a concrete example. These are the actual routing descriptions from two skills in Dean Peters' Product Manager Skills library:
director-readiness-advisor
Guide the PM-to-Director transition across preparing, interviewing,
landing, and recalibrating. Use when leadership scope is changing
and you need practical coaching.vp-cpo-readiness-advisor
Guide the transition to VP or CPO across preparing, interviewing,
landing, and recalibrating. Use when executive product scope is
changing fast.Now ask yourself: when a user types "I have a VP offer but I'm not sure I'm ready" — which skill should fire?
It should be vp-cpo-readiness-advisor. But with descriptions this similar, the model has no reliable basis to prefer it over director-readiness-advisor — both mention transitions, both mention preparing, both mention coaching through change.
The Anatomy of Routing Drift
These descriptions didn't end up similar by accident. They ended up similar because they were written the way a thoughtful engineer writes code: with consistency, shared vocabulary, and reused structure. The four phases (preparing, interviewing, landing, recalibrating) appear verbatim in both — a strong signal that one was templated from the other.
That's good documentation practice. It's terrible routing practice.
Routing descriptions are not documentation. They're instructions to the model about when to call a skill. Every word that appears in both descriptions weakens the signal on both. This pair doesn't just share words — it shares sentence structure, trigger conditions, and the four-phase framing that makes both descriptions feel interchangeable to a model that's never met your users.
The compounding problem: many real prompts contain only partial level signals rather than explicit titles. Nobody types "I am a Director seeking VP coaching." They type "I have a VP offer I'm evaluating" or "my exec peer relationships aren't landing." With descriptions this similar, even those partial signals get lost — the model has no meaningful basis to prefer one description over the other. Sharpen the descriptions, and the partial signals can do their job. For prompts with no level signal at all, a well-designed skill asks a single clarifying question — which is exactly what both of these skills already do.
This is routing drift: overlap that accumulates quietly, one reasonably-written skill at a time, until a meaningful fraction of your routing decisions are wrong.
Measuring It
Homingo is a CLI tool built specifically for this problem. Point it at your skills directory and run:
homingo lint --pair director-readiness-advisor,vp-cpo-readiness-advisorHere's what it finds:
Linting pair: director-readiness-advisor ↔ vp-cpo-readiness-advisor
Threshold: 90% | Model: claude-sonnet-4-20250514 | Sim: claude-haiku-4-5-20251001 (auto) | Prompts/pair: 10
✖ director-readiness-advisor ↔ vp-cpo-readiness-advisor — FAIL (50%, need 90%)
Results: 0 passed, 1 failed
50% accuracy — a coin flip on every ambiguous prompt. The severity badge isn't cosmetic: at this accuracy level, more than half of naturally-worded prompts route to the wrong skill.
Homingo then generates coordinated rewrite suggestions for both failing skills simultaneously, identifying the missing boundary as scope of responsibility — Director means single business unit, team leadership, first-time management; VP/CPO means multi-unit portfolio, P&L, board.
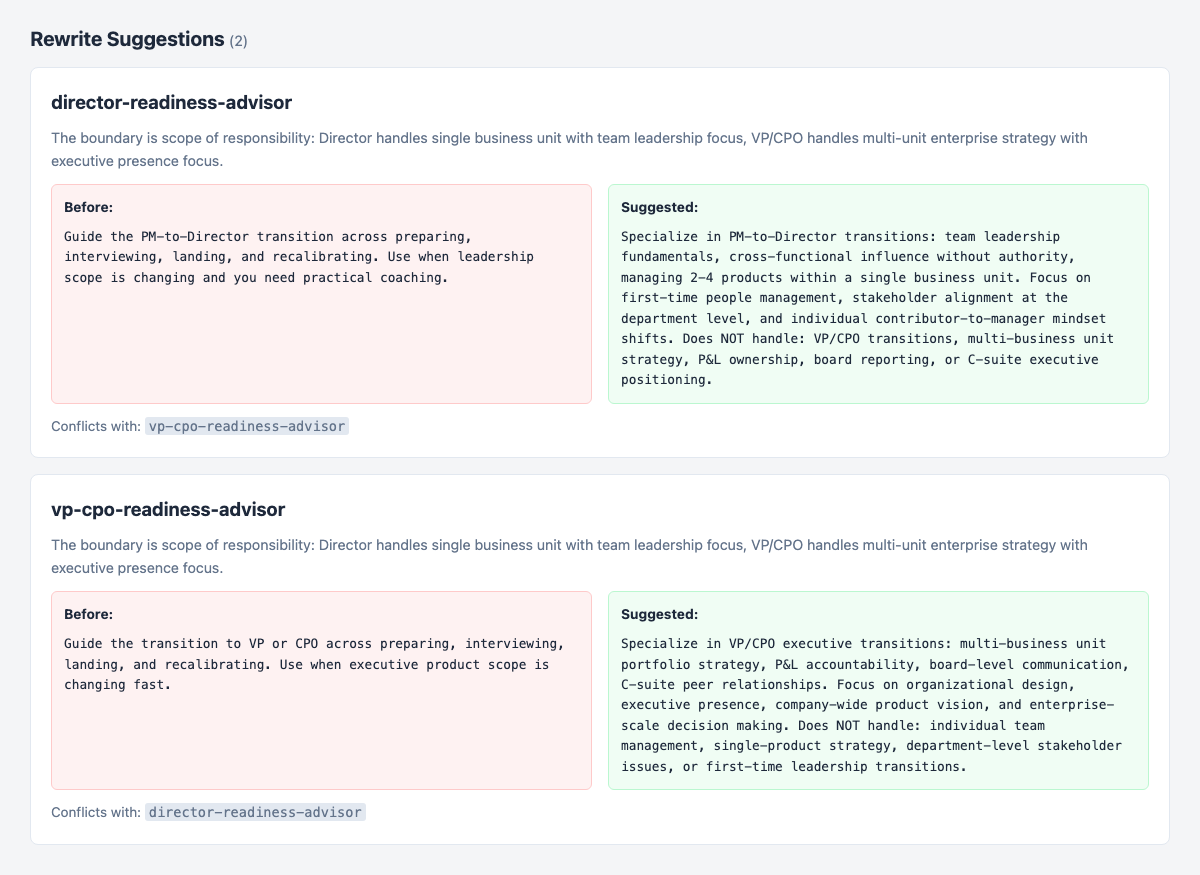
The suggested rewrites introduce something the originals lacked entirely: explicit Does NOT handle statements. Negative bounds are the most reliable disambiguation tool available to skill authors, and they're almost never written in first-draft descriptions.
These are suggestions only — no files have been modified. That's intentional: Homingo surfaces the problem and proposes a fix, but you review before anything changes.
Fixing It
--fix applies the rewrites to your SKILL.md files, re-tests routing accuracy against the same adversarial prompt set, and iterates until the pair clears the threshold:
homingo lint --pair director-readiness-advisor,vp-cpo-readiness-advisor --fix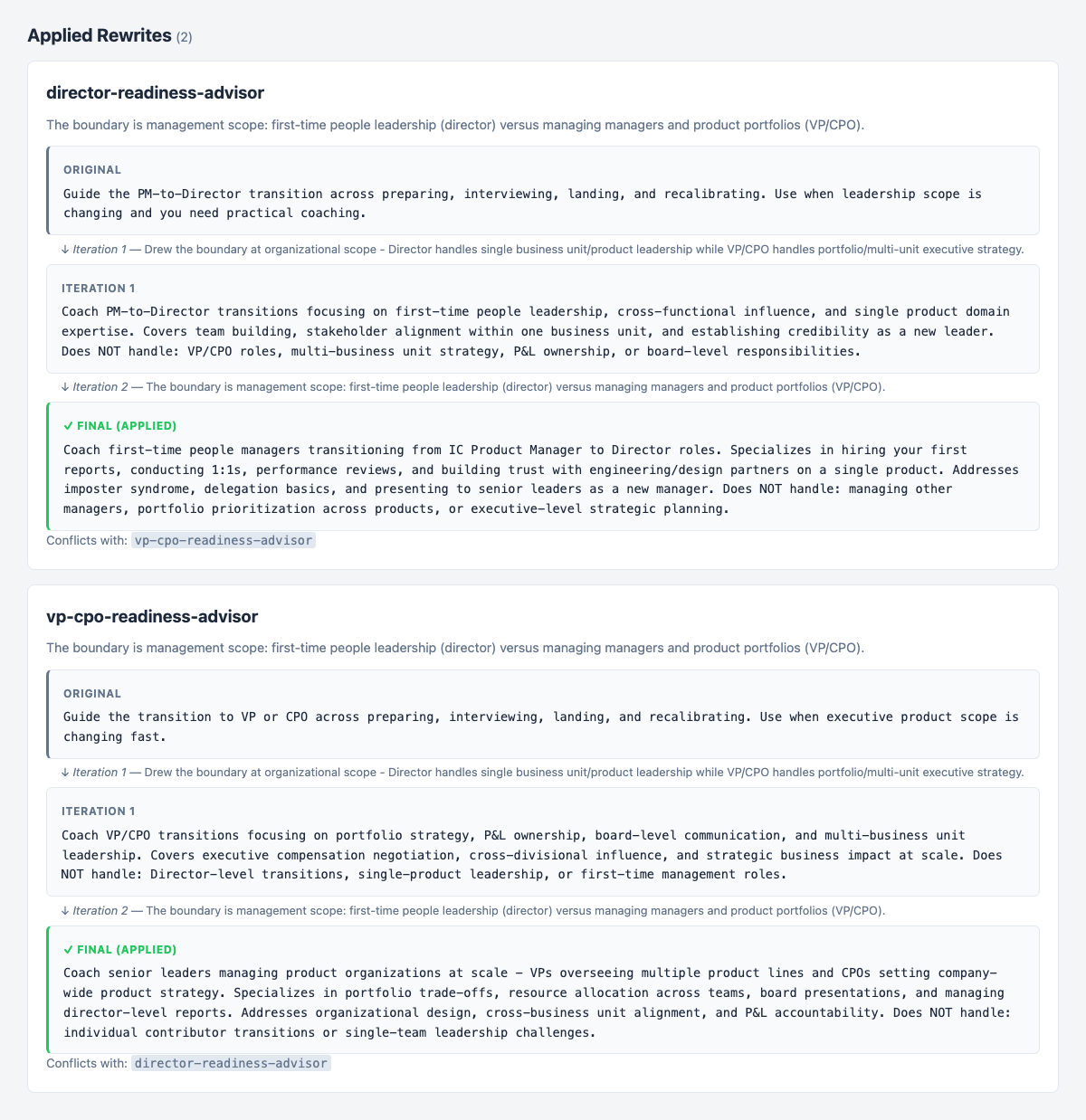
Two things worth noticing in that output:
Iteration 1 landed at 70% — better, but not enough. Homingo escalated, sharpening its framing from organizational scope to management scope. The second pass draws a crisper line: Director means managing people for the first time; VP/CPO means managing other managers. That single reframe pushed accuracy from 70% to 100%.
Both final descriptions contain explicit Does NOT handle statements. The originals had none. That addition is consistently the highest-leverage move in disambiguating overlapping skills — one sentence that permanently removes an entire class of misrouting.
What This Means If You're Building with Skills
The root cause here wasn't carelessness. The original descriptions were well-written. They communicated clearly what each skill does. The problem is that routing descriptions aren't evaluated in isolation — they're evaluated against every other skill in your fleet simultaneously. A description that reads as perfectly clear on its own can create genuine ambiguity when a sibling skill uses the same vocabulary.
A few principles that follow:
- Template reuse is a drift accelerator. If you scaffold new skills from existing ones without deliberately differentiating the routing descriptions, you're systematically accumulating overlap with every skill you ship.
- Say what you don't do. Anti-patterns are underused and high-value. "Does NOT handle: VP/CPO transitions" removes an entire prompt class from the wrong skill's candidate set. One line, permanent effect.
- Drift is a fleet property, not a skill property. You cannot catch this by reviewing individual descriptions. You need to evaluate all pairs and measure accuracy — which means you need tooling, not a code review.
- Drift is also continuous. Every new skill potentially conflicts with existing ones.
homingo lintbelongs in your CI pipeline, not just as a one-time audit.
What Comes Next: Scope Overload
Fixing the routing conflict exposed a second finding. After the rewrites, Homingo flagged both updated descriptions as scope-overloaded — each now covers too many distinct intents to be reliably called for the right sub-task.
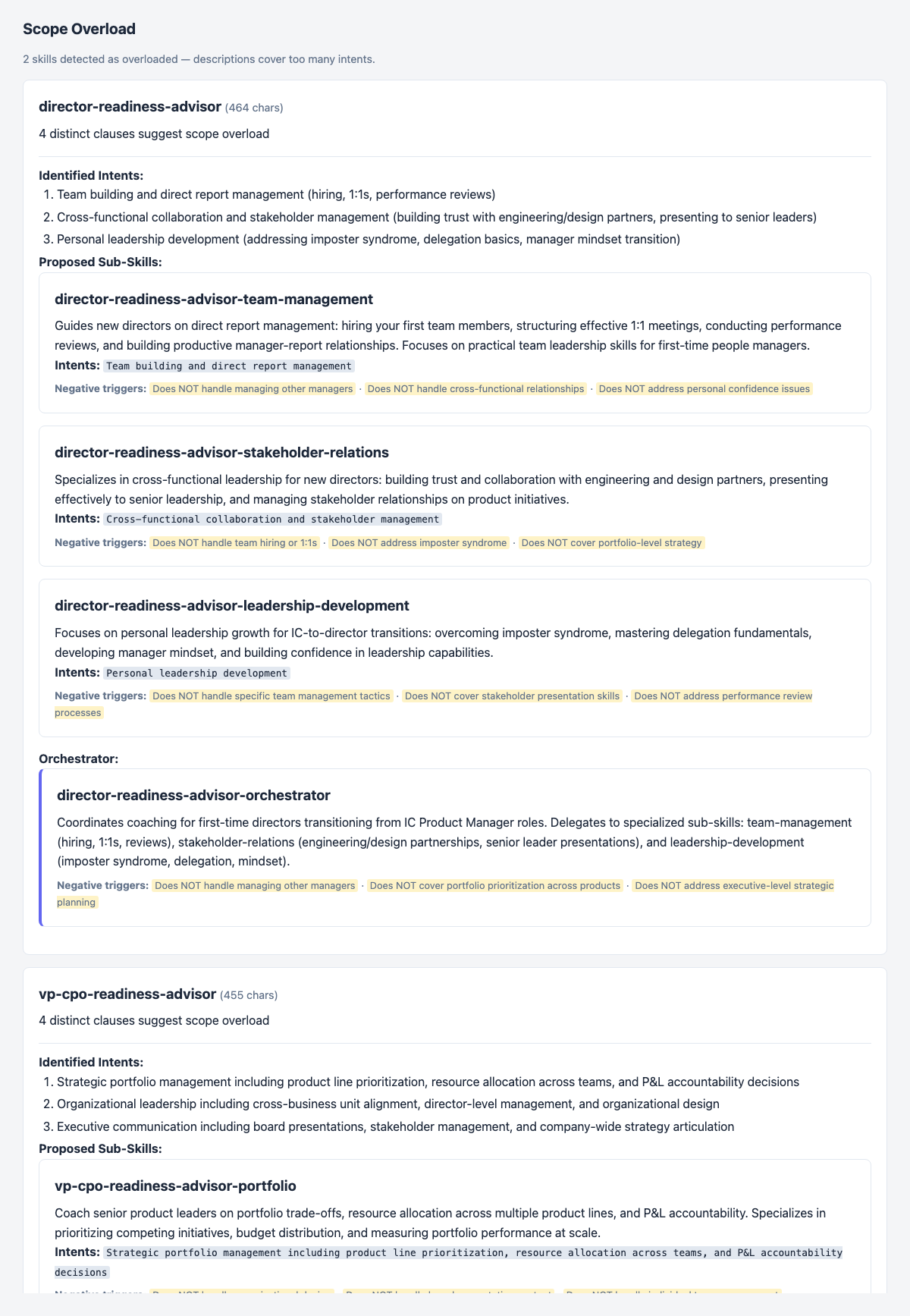
For director-readiness-advisor, the proposed split is:
director-readiness-advisor-team-management— hiring, 1:1s, performance reviewsdirector-readiness-advisor-stakeholder-relations— cross-functional trust, senior presentationsdirector-readiness-advisor-leadership-development— imposter syndrome, delegation, mindset
The routing conflict and the scope overload are related problems with the same root cause: descriptions that were written for human readers, not for models making routing decisions. Fixing one reveals the other.
Fix Routing Drift in Your Workflows
Homingo is free to start with — no API calls, runs locally in seconds — and will show you where your highest-overlap pairs are. From there, homingo lint gives you LLM-measured accuracy, and --fix handles the rewrites.
npm install -g homingo
homingo init
homingo scanYou can also explore the project on GitHub: Homingo.