The Question Your RAG Can't Answer
A Context Graph is a curated, typed knowledge graph that gives AI agents structured memory they can traverse and update.
A Context Graph is a curated, typed knowledge graph for AI agents. Instead of retrieving loose text chunks, the agent traverses explicit relationships, uses metadata attached to those relationships, and can write decisions back into the graph.
I've been thinking about what it would take for an AI agent to have real memory — not just recalled text, but structured knowledge it can traverse, update, and reason over with confidence.
To explore the idea, I built a proof of concept called Context Graph. The premise: instead of storing knowledge as documents or extracting a graph from text, you curate a graph directly as your source of truth. Typed edges. Temporal metadata. And critically, agents can write decisions back into it.
To make the comparison concrete, I ran the same question against three architectures: flat RAG, GraphRAG, and the Context Graph PoC. The question:
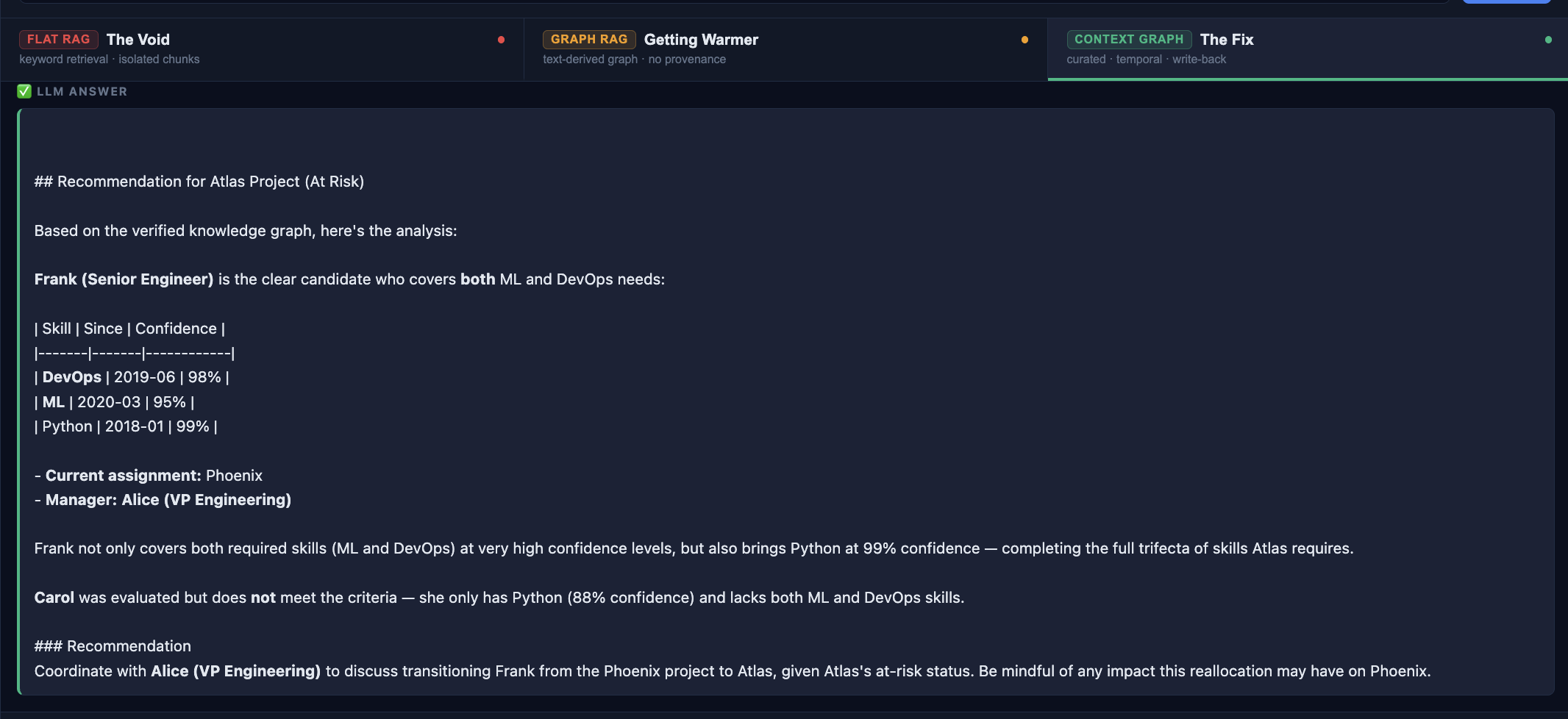
The Atlas project is at risk. Who has both ML and DevOps skills, isn't already assigned to Atlas, and who is their manager?
Four constraints. One question. Here's where each approach lands.
The Demo
Eight documents. Real employees, real projects, real skill profiles ... the kind of thing that lives in Confluence, or scattered across HR tools. The same corpus feeds all three approaches.
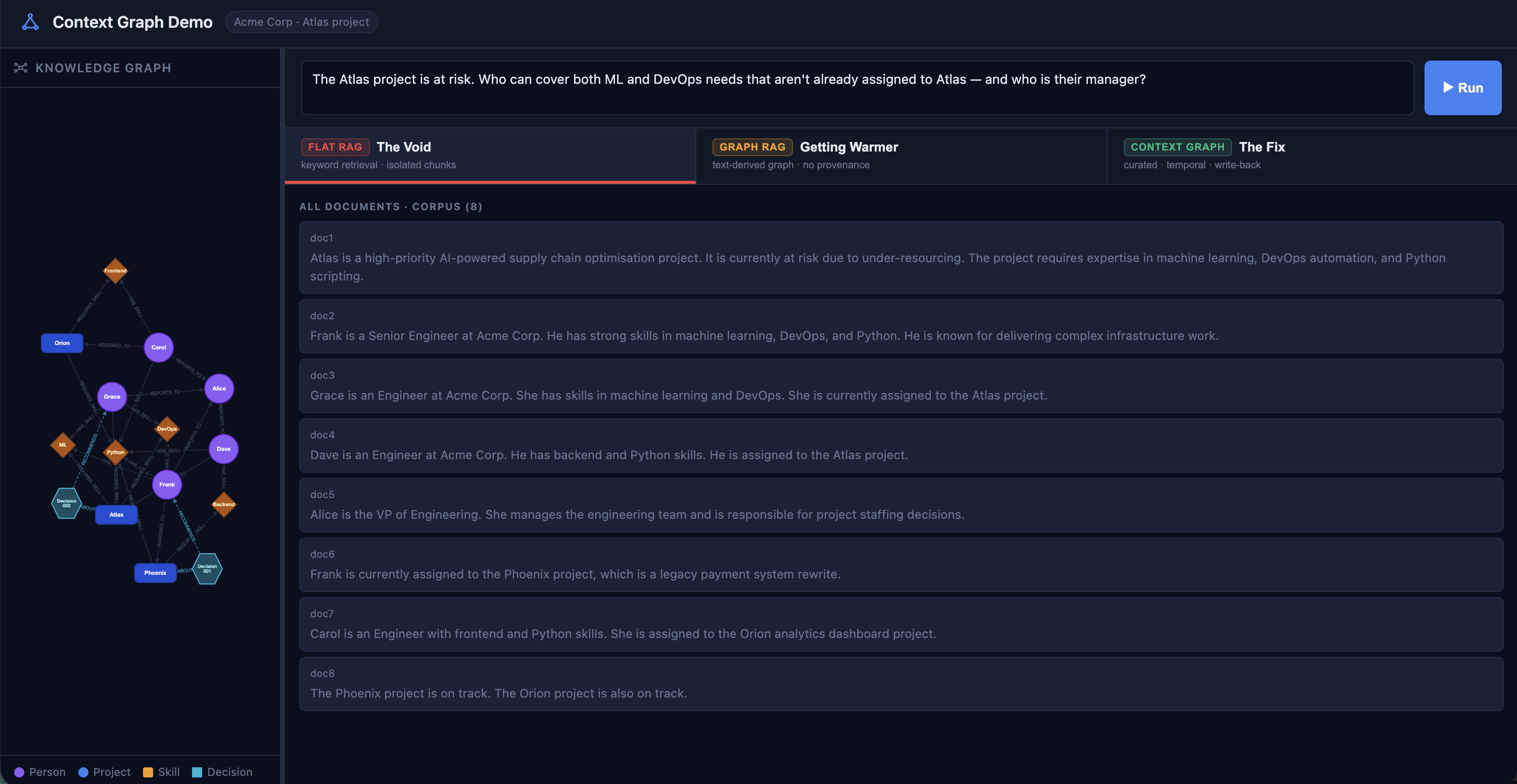
Flat RAG: Isolated Chunks, No Relationships
Flat RAG pulls the four most keyword-relevant chunks. For this question, that's:
- the Atlas requirements doc,
- Frank's skills profile,
- Grace's record, and
- Alice's overview.
Document 6, the one that establishes Frank's actual assignment to Phoenix, doesn't score high enough on keyword overlap to make the cut.
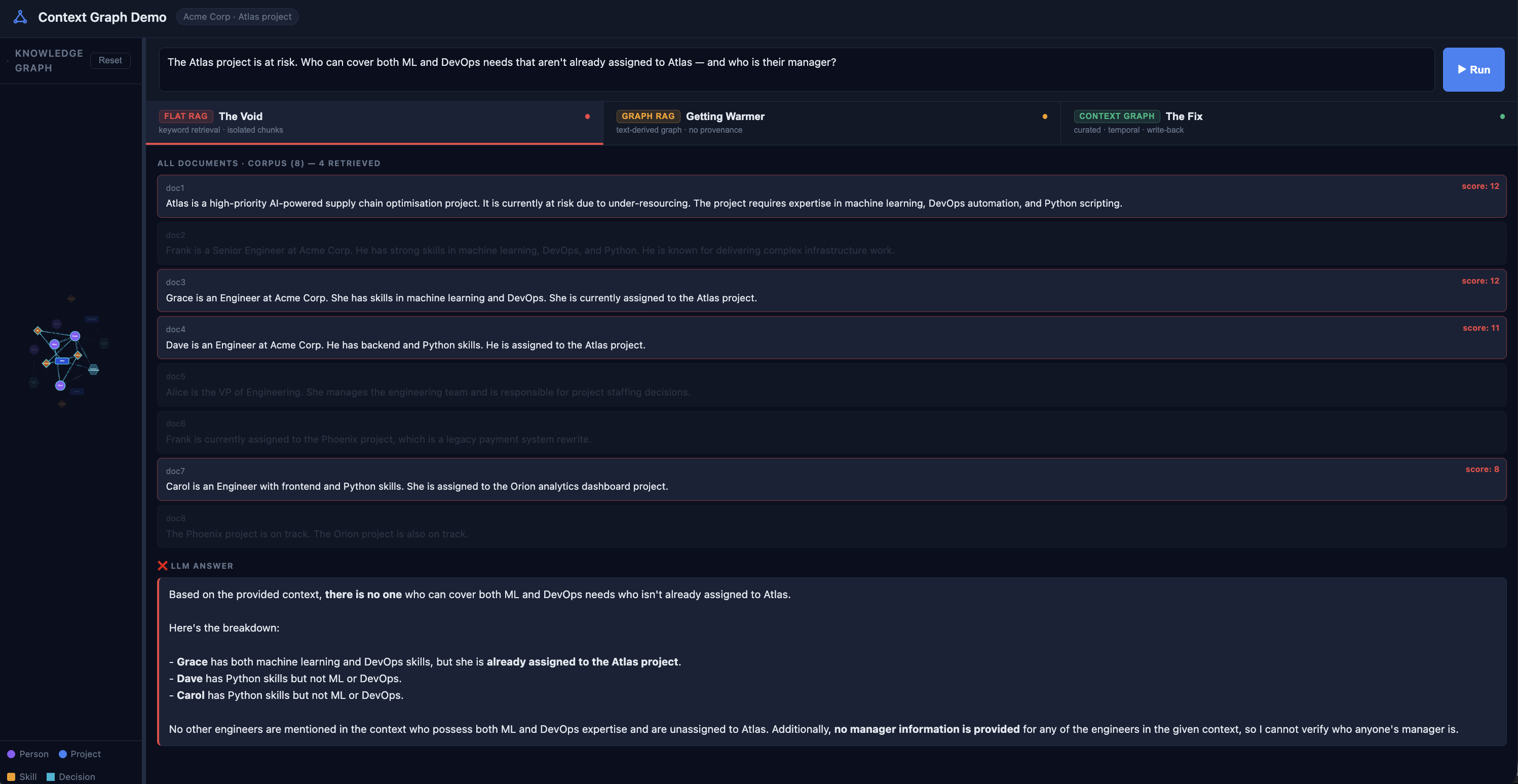
It missed Frank entirely. The manager question gets a hard no: No managers are identified in the provided context.
The information exists in the corpus. It just arrived as isolated sentences with no relationship between them. Flat RAG is a bag of sentences. Bags don't have edges.
GraphRAG: Better, but Still Inherits Your Blind Spots
GraphRAG extracts a graph from the text corpus using an LLM. It identifies entities and relationships, builds a knowledge graph, then traverses it at query time. An improvement over raw retrieval.
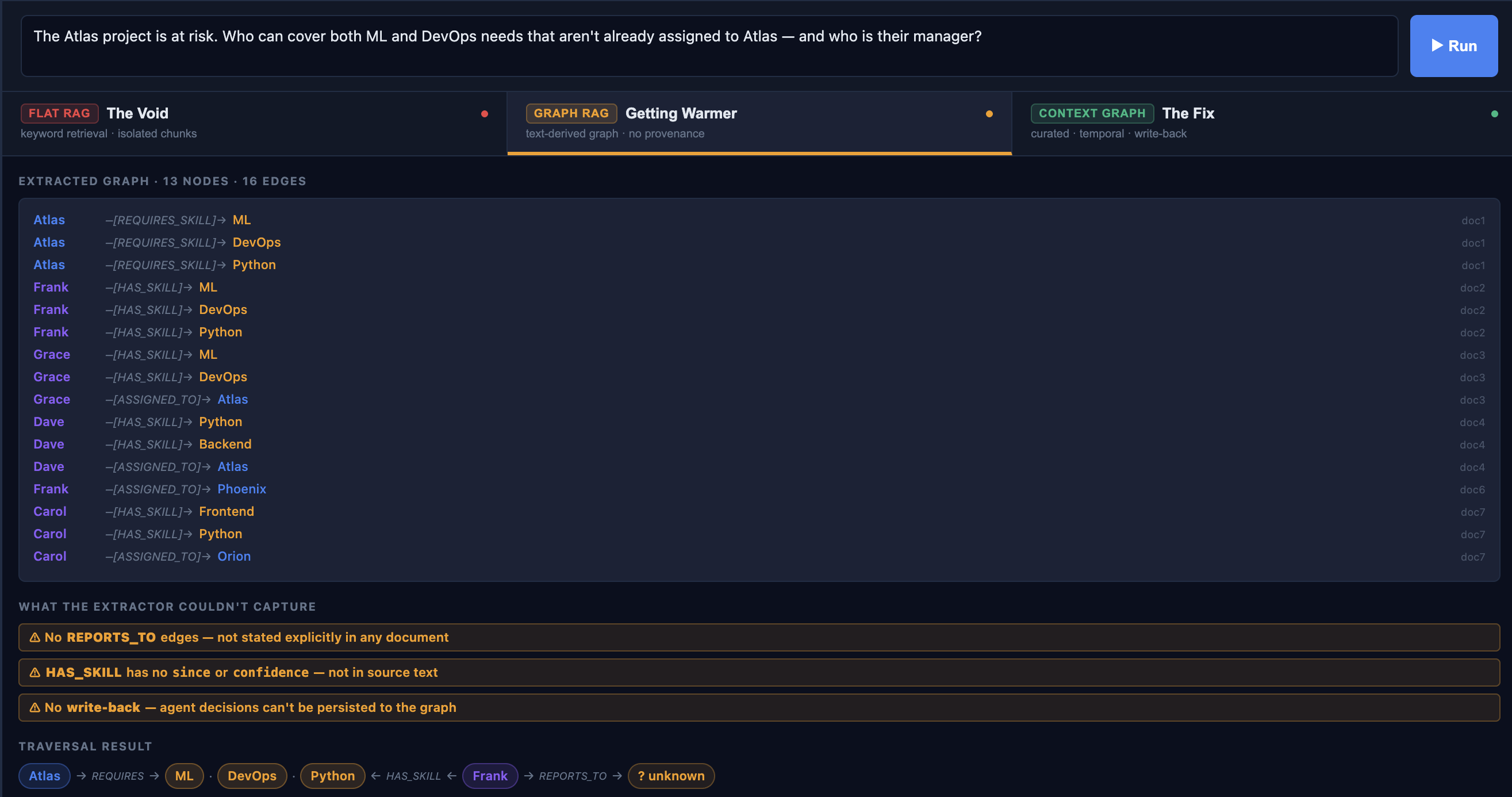
The traversal finds Frank. But then:
No REPORTS_TO edges. Document 5 says Alice manages the engineering team ... too vague for a reliable extraction. An extractor shouldn't confidently produce Frank -[REPORTS_TO]-> Alice from that sentence. So it doesn't.
GraphRAG inherits every omission in your source documents. And it can only read, i.e., when the agent makes a decision, that decision disappears.
Context Graph: Curated, Temporal, Write-Back
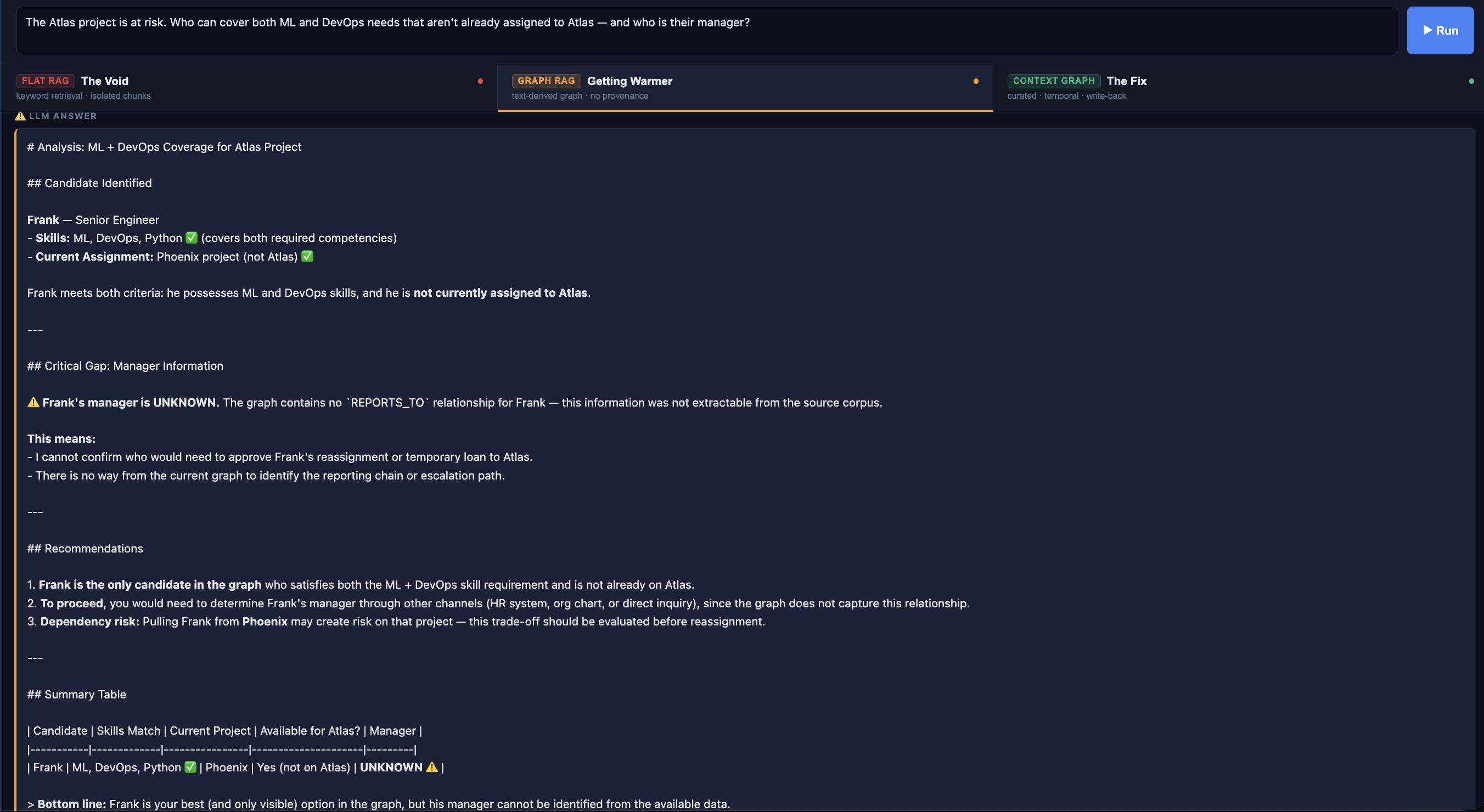
This is the pattern I wanted to explore. A Context Graph isn't extracted from text. It is maintained as the source of truth. Relationships are written explicitly, at the time they become true, with the metadata that actually matters to decisions.
(Frank)-[:HAS_SKILL {since: "2019-06", confidence: 0.98, endorsedBy: "Alice"}]->(DevOps)
(Frank)-[:REPORTS_TO]->(Alice)The traversal can now follow a verified 4-hop path:
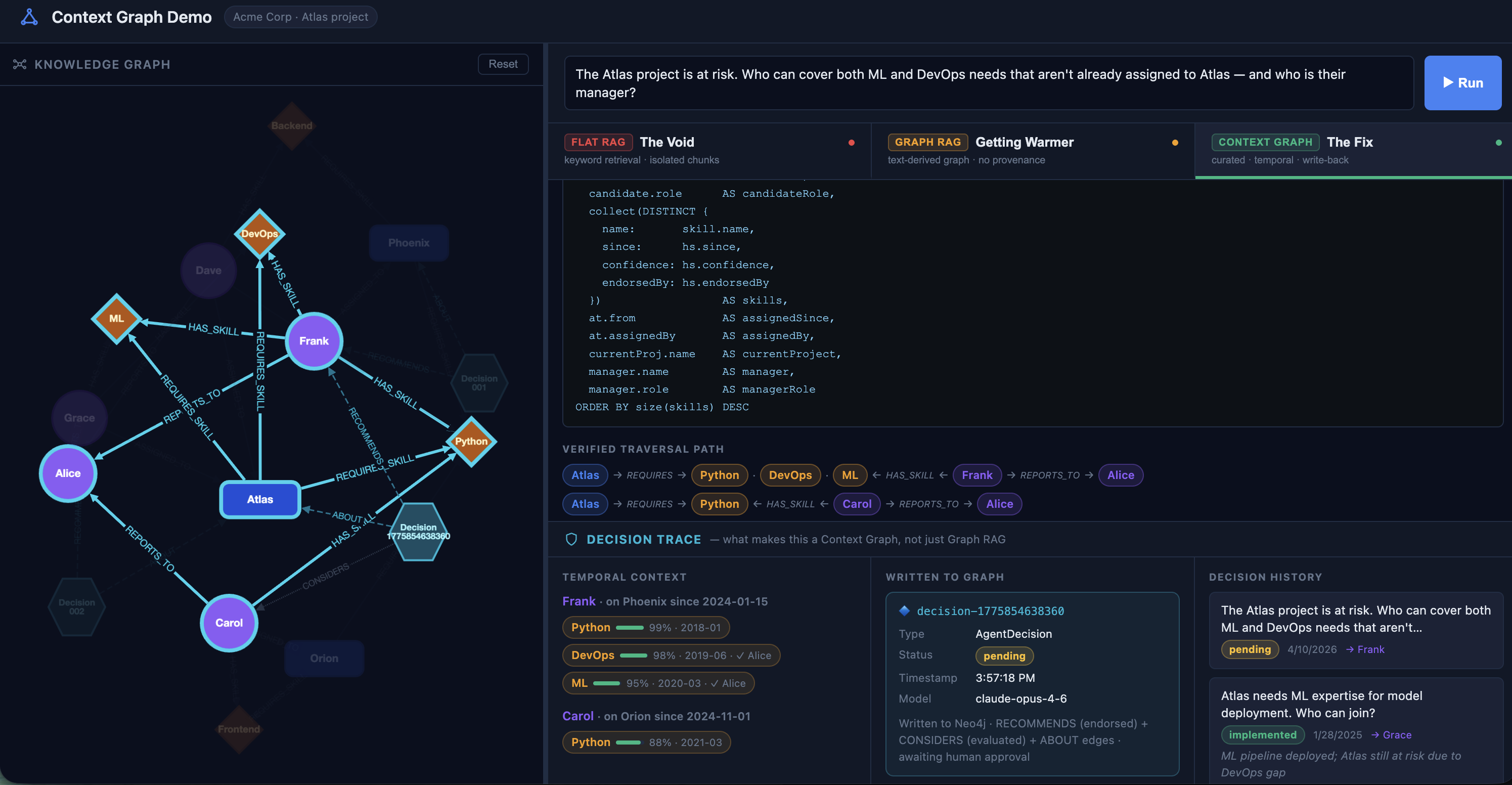
The Part That Interests Me Most: Write-Back
Notice the Decision Trace panel. The agent's recommendation is now a first-class node in the graph: an AgentDecision with typed edges to Frank, to Atlas, with a timestamp and a status.
You can query it. You can update it when Frank actually moves. You can see that the same question was asked a year ago, resolved to Grace, and its outcome is recorded. That history becomes part of the context for every future query.
This is what auditable AI could look like in practice. Not just what did the model say but what was recommended, to whom, when, based on what, and what happened next.
What This PoC Shows
| Capability | Flat RAG | GraphRAG | Context Graph |
|---|---|---|---|
| Finds the right candidate | ❌ | ✅ | ✅ |
| Knows the manager | ❌ | ❌ | ✅ |
| Temporal skill metadata | ❌ | ❌ | ✅ |
| Agent decision write-back | ❌ | ❌ | ✅ |
| Graph quality | N/A | Only as good as docs | Source of truth |
The PoC is deliberately narrow: a staffing scenario, a small corpus, a single domain. But the pattern generalizes. Anywhere an agent needs to reason over relationships, not just retrieve text, a curated graph gives it a fundamentally better foundation to work from.
The Honest Trade-Off
Context Graph requires more upfront investment than either RAG approach. Someone has to write the edges. That's real work, and the right answer for whether it's worth it depends on what's at stake.
But for domains where AI is making consequential decisions — staffing, routing, resource allocation, diagnosis — the alternative is an agent that confidently guesses a manager's name or quietly omits that the same decision was made and reversed six months ago.
The interesting thing to watch in the demo isn't the answers. It's the knowledge graph panel after the Context Graph query runs. A new Decision node appears in real time, edges radiating out to Frank, to Atlas, anchoring the recommendation in the structure of everything else the system knows.
That's the direction I think agent memory is going ... or, needs to go.